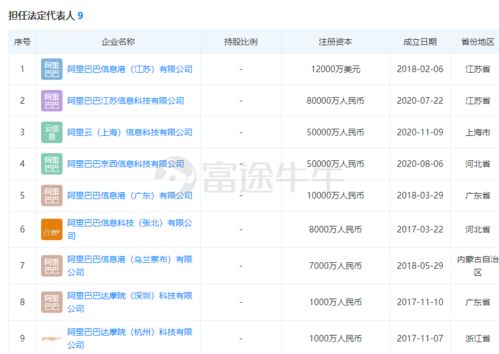
在數據庫系統的設計與應用中,數據獨立性被視為一項根本性的設計目標,它為現代信息系統的有效運行與長期維護奠定了堅實基礎。數據獨立性主要體現在兩個方面:物理獨立性與邏輯獨立性,它們共同構成了數據庫系統強大適應性的核心。
數據獨立性的雙重內涵與價值
1. 物理數據獨立性: 指用戶的應用程序與數據庫中數據的物理存儲方式相互獨立。這意味著,當數據庫的存儲結構、存取方法、硬件設備或文件組織發生改變時(例如,從機械硬盤遷移到固態硬盤,或調整數據塊大小),無需修改現有的應用程序。數據庫管理系統(DBMS)通過其內部的三級模式結構(外模式、模式、內模式)以及它們之間的兩層映射(外模式/模式映射、模式/內模式映射)實現了這種隔離。物理獨立性極大地保護了應用軟件的投資,使得系統能夠靈活地進行底層性能優化和硬件升級,而無需觸動上層的業務邏輯。
2. 邏輯數據獨立性: 指用戶的應用程序與數據庫的邏輯結構(即全局邏輯結構,模式)相互獨立。當數據庫的概念模式發生改變時(例如,增加新的實體、屬性或關系,或在無損連接的前提下修改表結構),只需要調整外模式/模式映射,而基于原有外模式編寫的應用程序可以保持不變。邏輯獨立性使得數據庫能夠適應業務需求的演進和變化,支持信息系統的迭代開發與功能擴展。
數據獨立性對信息系統運行維護服務的深遠意義
數據獨立性并非一個孤立的特性,它與信息系統運行維護服務的質量、成本與效率息息相關。運行維護服務旨在保障信息系統安全、穩定、高效、持續地運行,并滿足不斷變化的業務需求。數據獨立性在此過程中扮演著至關重要的角色:
1. 提升系統可維護性與可擴展性: 由于應用程序與數據存儲細節解耦,運維團隊在進行數據庫的物理調整(如分區、索引重建、存儲遷移)或邏輯結構調整(如范式優化、增加視圖)時,影響范圍可控,風險顯著降低。這簡化了維護流程,縮短了維護窗口,并使得系統擴容和架構演進變得更加平滑。
2. 降低長期運維成本: 避免了因數據存儲方式或結構變動而引發的大規模應用代碼重寫。這直接減少了在系統生命周期內因技術更新或業務變化而產生的人力、時間和資金投入,保護了企業的IT資產。
3. 增強業務連續性與靈活性: 在需要快速響應業務變化的場景下(如新的報表需求、業務規則調整),數據庫管理員可以通過創建新的視圖或調整邏輯模式來滿足需求,而無需等待冗長的應用開發與測試周期。這提升了運維服務對業務部門的支撐能力。
4. 保障數據安全與管理效率: 通過外模式機制,可以為不同用戶或應用提供定制化的數據視圖,隱藏敏感或無關數據。這在運維層面簡化了權限管理,實現了數據訪問的最小權限原則,有利于安全策略的實施與審計。
結論
數據庫系統之所以必須具有數據獨立性,是因為它是應對信息環境復雜性、多變性以及保障信息系統長期健康運行的內在要求。它不僅是數據庫理論的一個優美設計,更是連接穩定數據基礎與動態業務需求的韌性橋梁。對于信息系統運行維護服務而言,一個具備良好數據獨立性的數據庫,意味著更低的維護復雜度、更高的變更靈活性、更強的風險控制能力以及更優的總體擁有成本。因此,在系統規劃、設計與選型階段,重視并確保數據獨立性,是未來高效、敏捷運維的智慧投資。